

首先我们基于上节Cassandra学习—结构学习了解到在关系型世界之中,查询是非常次要的东西。关系模型假设,只要正确地建立了表,总能获取到所需要的数据,即使这是以使用很多复杂的子查询或是join语句为代价的。(cassandra中并无joins,也无参照完整性,)
应用实例
1、数据模型设计
首先我们基于上节Cassandra学习—结构学习了解到在关系型世界之中,查询是非常次要的东西。关系模型假设,只要正确地建立了表,总能获取到所需要的数据,即使这是以使用很多复杂的子查询或是join语句为代价的。(cassandra中并无joins,也无参照完整性,)
但是在Cassandra中,不是从数据模型开始的,而要从查询模型开始。
下面我们将来简单描述下我们使用的例子:客户预定酒店
这里的的概念域包括酒店、入住的客人、每个酒店房间的集合以及预定房间的记录, 也就是某个客人在某个房间呆的一段时间(称为停留时间)。酒店一般都会保留一个 兴趣点的集合,包括公园、博物馆、购物场所、古迹或者位于宾馆附近的某些地方, 游客可能会在停留期间前去休闲。宾馆和兴趣点都需要维护地理信息,这样可以在 地图上查找,或是计算距离。
现在来看看如何设计使用Cassandra的应用。首先要确定查询。我们希望做如下这些事情:
- 酒店
- 客人呆在酒店
- 每家酒店的房间list
- 房间的rate和是否可预订
- 房间对应的预订情况
- 每家酒店往往还会有一个Point of Interest功能,显示酒店附近可供游玩的地方.
1.1 关系型数据库设计
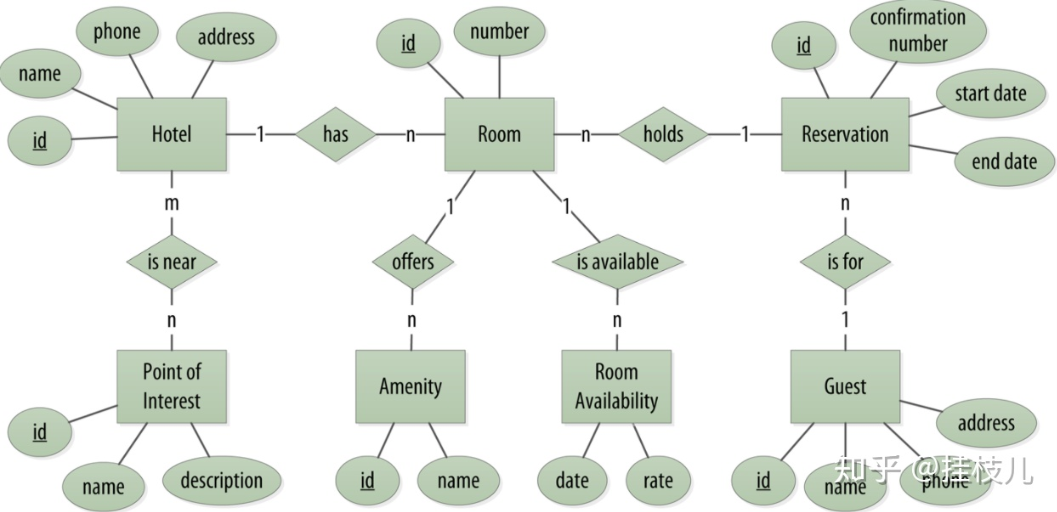
如果我们用关系型数据库来表达上面的业务场景的话,表与表之间的关联关系可以这样表达:
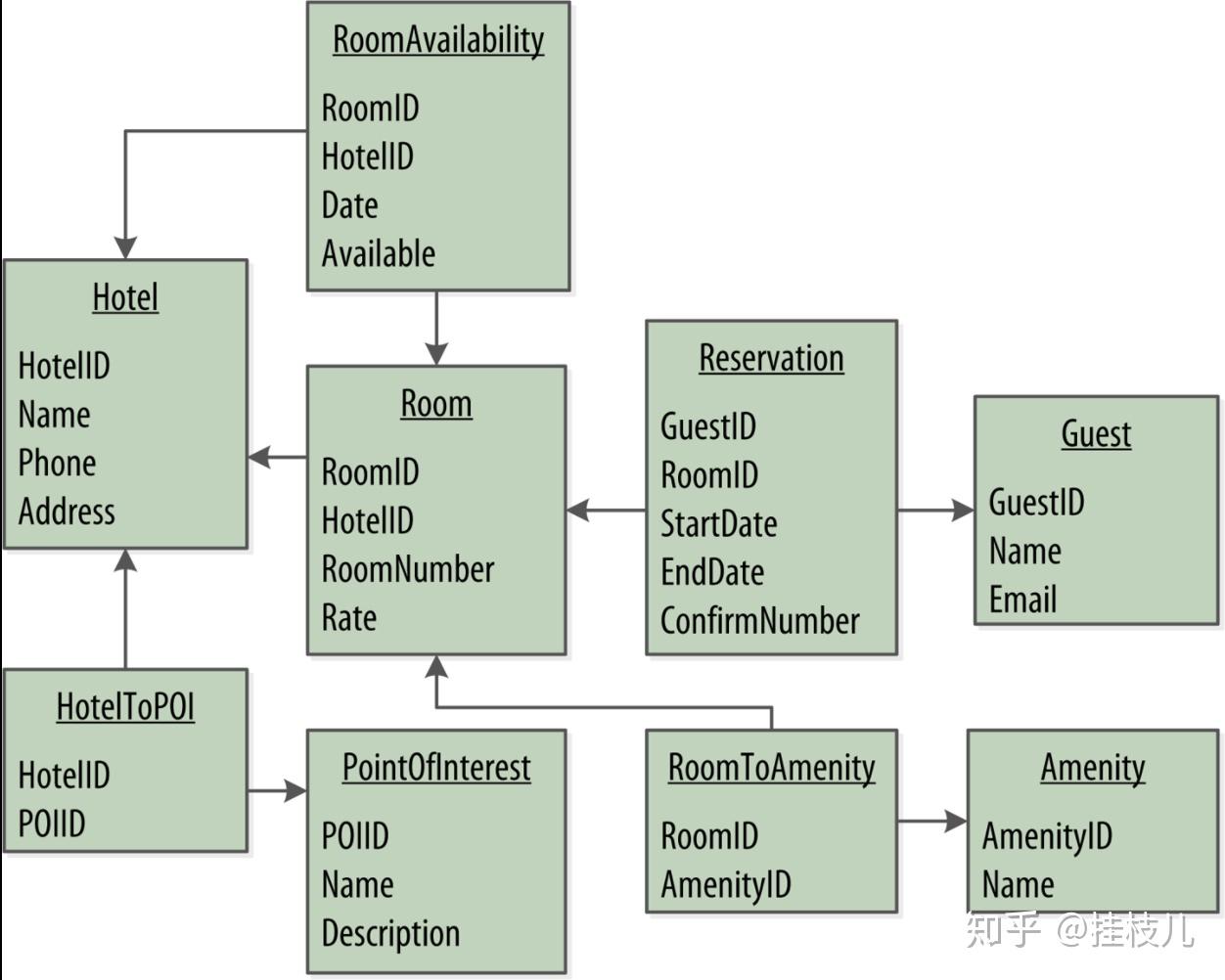
1.2 关系型数据库与Cassandra的区别:

1.2.1 不存在Join
在cassandra上不存在join的操作。如果你需要在Cassandra中做一个类似于SQL上join的操作,你要么需要在客户端做这个事,要么就需要创建一个反范式的扁平表来直接存储join的结果,在Cassandra中更倾向于做一个扁平表。
1.2.2 无参照完整性
虽然Cassandra中有batches操作,但是Cassandra本身并没有参照完整性的概念。在SQL中你可以在表中声明foreign key来引用其他表的primary key,但Cassandra中没有这样的硬性要求。
1.2.3 Denormalization
在SQL数据库中范式化很重要,但是在Cassandra中却不是这样,Cassandra在数据反范式化时效率最高,并且也是最常见的数据结构。
1.2.4 查询优先的设计模式
QUERY FIRST DESIGN。
在关系型数据库中,我们从概念层面表达我们的数据,并且依此来设计table,并且给每一张表设计primary key和foreign key。当我们需要进行多表查询的时候,我们就会用到SQL的join功能。这个设计的好处是,我们想要查询的数据无论有多复杂,我们总能通过设计一天复杂的SQL查询语言来解决数据需求问题。
与之对立的是,SQL并不是从数据模型开始设计的,你必须从你的查询需求来设计数据模型。在Cassandra中我们会优先根据我们的取数需求,来设计数据的存储方式 —— 想想一下在业务场景中最常见的查询语句,然后设计table来支持它。
贬低者通常会说优先设计查询会限制应用层面的设计,也会限制我们的数据模型。但其实认真想想,慎重考虑你收集数据的目的,然后提炼成查询语言是很合理的。
1.2.5 为了最优存储而设计
DESIGNING FOR OPTIMAL STORAGE。
在关系型数据库中,用户可以很方便的看到数据是如何存储在硬盘上的,并且很少有人提及我们的数据模型会如何影响数据在硬盘上的存储。However,在Cassandra中我们一定要考虑到这点。因为Cassandra中同一张表会存在不同的硬盘上,所以我们一定要将相关的列存在同一个table中。
使用Cassandra设计表时候一个关键目标是 我们需要最小化针对一个query我们需要search的partitions的数量。因为在Cassandra中我们一个partition的数据是一个不能跨节点的存储单元。一个只需要查询一个节点上数据的query往往表现是最优的。
这里怕翻译的有问题我把原文也放出来把

1.2.6 排序是一个设计时就要考虑的点
SORTING IS A DESIGN DECISION.
在关系型数据库中,数据的排序我们可以灵活的通过ORDER BY命令来进行指定排序的返回,也就是说指定的排序必须在查询的时候才能够做调整。
在Cassandra中,排序的处理方式有些不同;他是一个设计的时候就需要考虑到的事情。针对一个query的结果排序方式是固定的,完全是有建表时的clustering columns决定的。CQL语法并不支持ORDER BY ,只支持升序或者降序的针对Clustering Columns来决定。
1.3 cassandra数据库设计
1.3.1 需求分析
- Q1. Find hotels near a given point of interest.查找附近特定兴趣点的酒店。根据兴趣点查酒店
- Q2. Find information about a given hotel, such as its name and location.查找有关特定酒店的信息,例如其名称和位置。
- Q3. Find points of interest near a given hotel.查找特定酒店附近的景点。
- Q4. Find an available room in a given date range.查找给定日期范围内的可用房间。
- Q5. Find the rate and amenities for a room. 查找房间的价格和设施。
针对以上取数需求下面会简写成Q1,Q2,Q3….
针对上面的场景,我们第一需要保证的需求肯定就是客户预定酒店的需求,这当中会包括的步骤有:
- 选择可定的房间
- 输入客户信息
这就需要数据能够接受查询预定以及客户实体信息
除了针对客户需求需要满足的查询,我们从数据模型的角度出发,也需要考虑设计能够存储预定信息以及客户信息的表,针对客户的预定查询需求,我们可能遇到的查询方式会有:
- Q6. Look up a reservation by confirmation number.通过确认号码查找预订。
- Q7. Look up a reservation by hotel, date, and guest name.按酒店,日期和客人姓名查询预订。
- Q8. Look up all reservations by guest name.按客人姓名查找所有预订。
- Q9. View guest details.查看客人详细信息
以上的查询需求我们可以通过下面的流程图来进行表达,箭头代表当前箭头能够代表的查询,后续的查询对前序的查询会存在依赖关系。
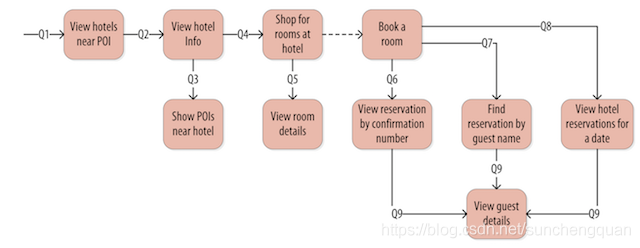
1.3.2 逻辑化数据模型(Logical Data Modeling)
现在我们想象了一些查询方式,接下来就要考虑如何设计这个Cassandra表了。首先,我们需要创建一个logical model,来抓住这些实体间预计关系上的概念模型。
表名的创建方式也很简单,声明我们查询时候的查询实体,然后如果我们也有查询附带的attribnute信息的话,把attribute 加一个下划线,比如我们如果要根据POI来查询附近的酒店信息,我们的名字就可以写成

然后,我们就需要设计我们针对这张表的时候需要用到的primary key了,以此来添加我们的partition key columns,同时也需要加入clustering columns来保证数据间的唯一性。
partition key负责数据存储的node, clustering node负责数据存储的唯一性。
在Cassandra中Primary Key的重要性:
Primary key的设计非常重要,因为他会决定在每个partition中会存储的数据数量,进一步的会影响Cassandra的查询效率。
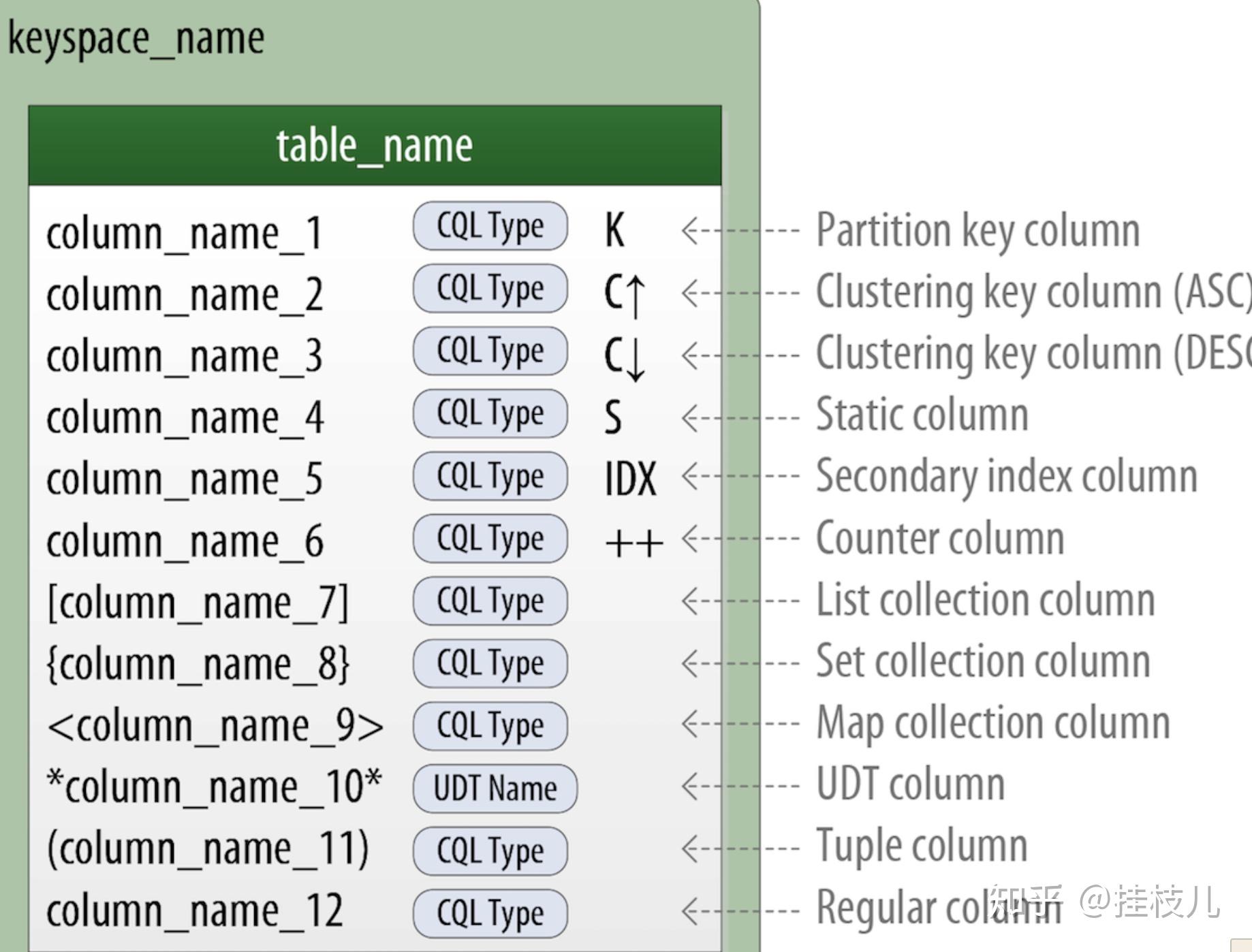
1.3.2 建表准备 CHEBOTKO DIAGRAMS
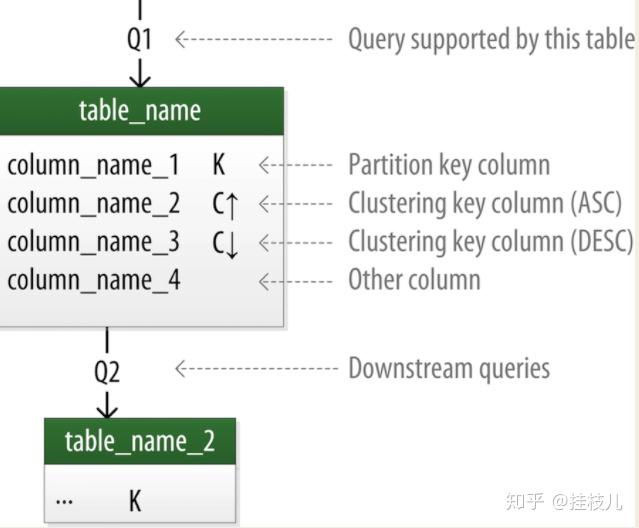
每一张表都会显示他的title和一系列的表名。K 代表是Primary key, 向上乡下的箭头代表clustering key的排序方向。表和表之间的连线代表每一张表希望可以支持的查询语句
1.3.3 建表(针对前5个问题)
下图就是书中对针对酒店,POI,房间以及便利设施的查询。能够与SQL数据库发现的一个人非常显著的区别就是,在CASSANDRA中我们没有针对房间或者遍历设施是的单独表。这是因为目前的查询需求中没有针对这两者的直接查询。
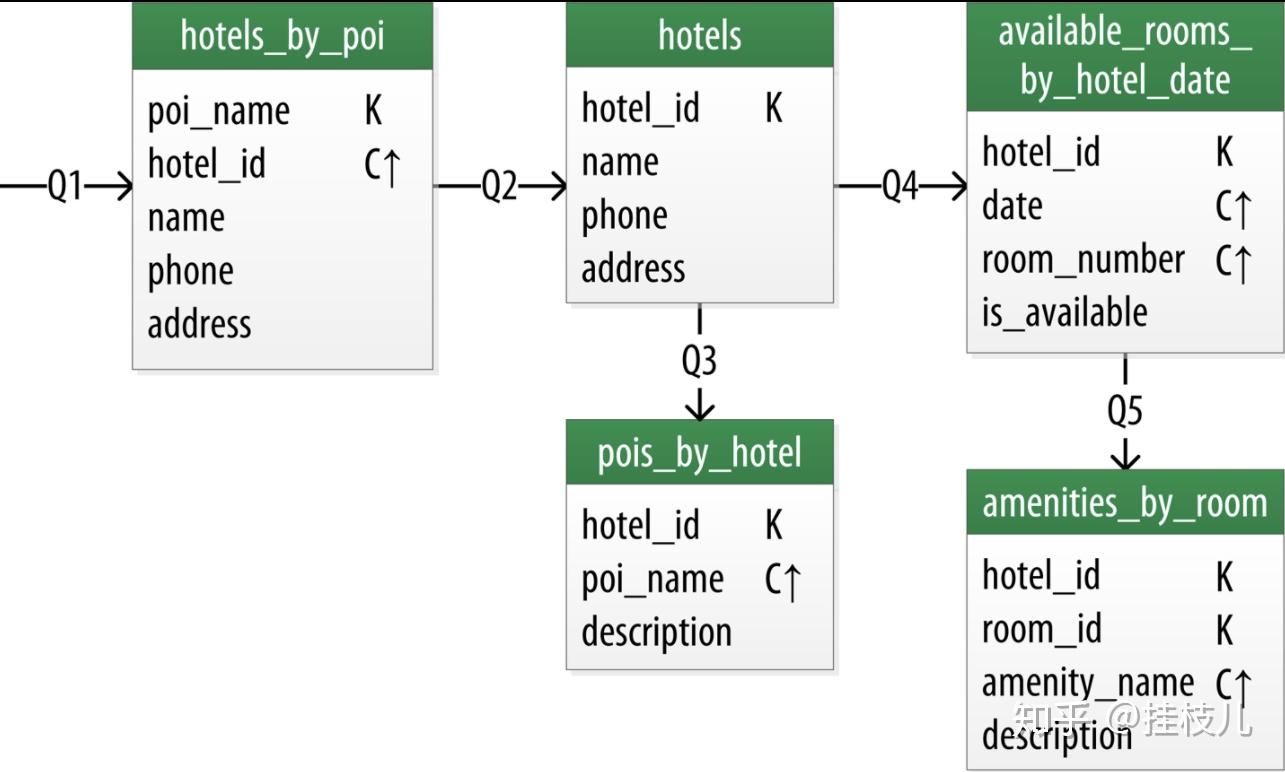
我们接下来看一下这一张表的细节:
我们的Q1.查询是需要找到酒店对应的POI 。所以我们就可以根据表1来直接取得一个key下的所有hotelid.。因为一个POI附件往往不止一家酒店,所以我们为了保证数据唯一性把hotel_id也作为了一个Cassndraid来存储。
再次强调Cassandra的建模我们一定要保证数据的唯一性,否则数据会被overwrite。
然后我们来看第二个Q2. Find information about a given hotel, such as its name and location.这个数据的使用场景是是我们需要一家酒店的详细信息,一个方法是把所有的对应信息都储存在hotelbypo这张表中,但你可以选择只把你工作流中需要的数据加入数据,所以我们分开存储。
从我们的diagram上可以观察到,hotelbypoi这张表只会用来显示一系列在景点附近的酒店基础信息,当一个用户选择去query酒店的详细信息时,我们就可以调用Q2,获取酒店的详细信息。因为我们已经从Q1中获取到了Q2的信息,所以我们就将使用Q1的结果来对Q2进行查询。
Q3. Find points of interest near a given hotel.这个其实就是Q1的反转查询,但这一次我们需要每一个POI的详细信息,所以我们新建一个poisbyhotel表,并加入描述信息。
接下来我们考虑Q4. Find an available room in a given date range.,注意这个查询会需要一个其实日期以及一个结束日期,所以我们肯定就需要把date作为一个clustering key,并使用hotel_id作为pariamry key聚合所有的房间数据。这个表我们就叫做available room by hotel date
范围查找
在Cassandra中,我们会使用clustering column来保存你需要访问时间段的数据,记得之前写过clustering columns的顺序非常重要。
1.3.4 建表(针对预定的逻辑数据模型)
接下来我们看针对预定查询的逻辑数据模型图,可以观察下图发现我们的数据是反范式的,一样的数据出现在了多张表中(当然keys不同)
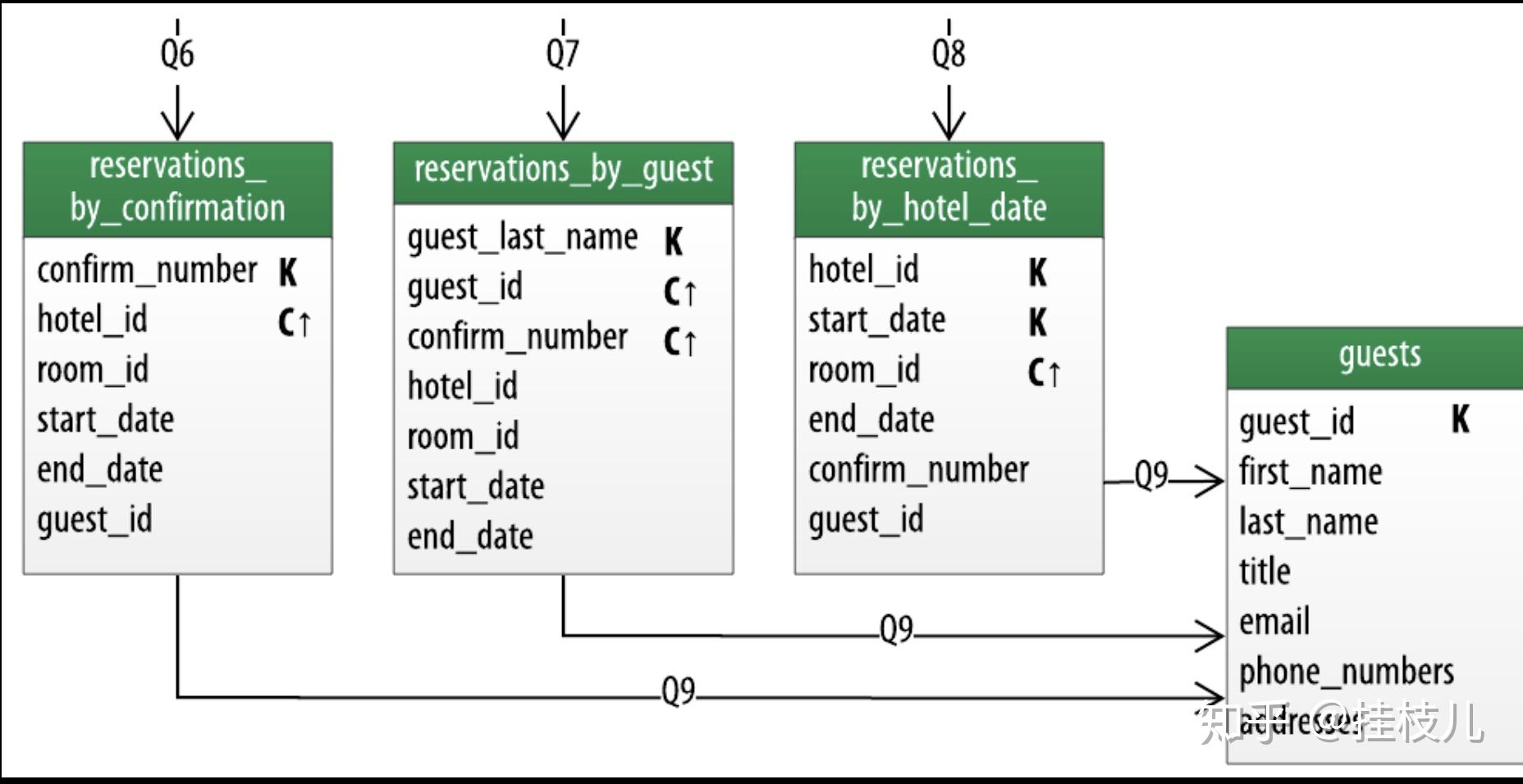
为了满足Q6. Look up a reservation by confirmation number,我们做了reservation by confirmation表。可以通过唯一的预定号查询到对应的预定详细信息。
如果客户没有confirmation num,那么reservation by guest就可以通过客户名字查到预定号,也是Q7.Look up a reservation by hotel, date, and guest name.的解决方式
酒店员工可能会根据日期以及酒店来看酒店最近的售卖情况,这也是Q8. Look up all reservations by guest name.做的事。
最后,我们创建了一个guets表,这里是一个我们存储客户详细信息的数据表。
要考虑多方的查询需求,in this case,客人的,as well as 酒店员工的。
注:更多的Cassandra表模式
另一个在Cassandra表模式中非常常见的数据模式就是time series存储。在这个模式中,一系列的数据模式以特定的时间间隔存储,这个时间戳将会被用来当partition key。这种模式在商业分析,传感器数据管理以及科学实验的场景中非常常见。
除了上面说到的场景,这个模式也非常适用于其他的场景,比如银行应用,Cassandra非常适合使用时间序列的数据分析。
但需要注意的是,除了时间序列之外,尽量不要简单地将Cassandra作为队列来使用,因为有tombstone的机制。删掉的数据也会需要scan,降低效率的!
1.3.5 建立实体表
一旦我们把Logical Data Model跑通了,真的建立实体表相对来说就很简单了。
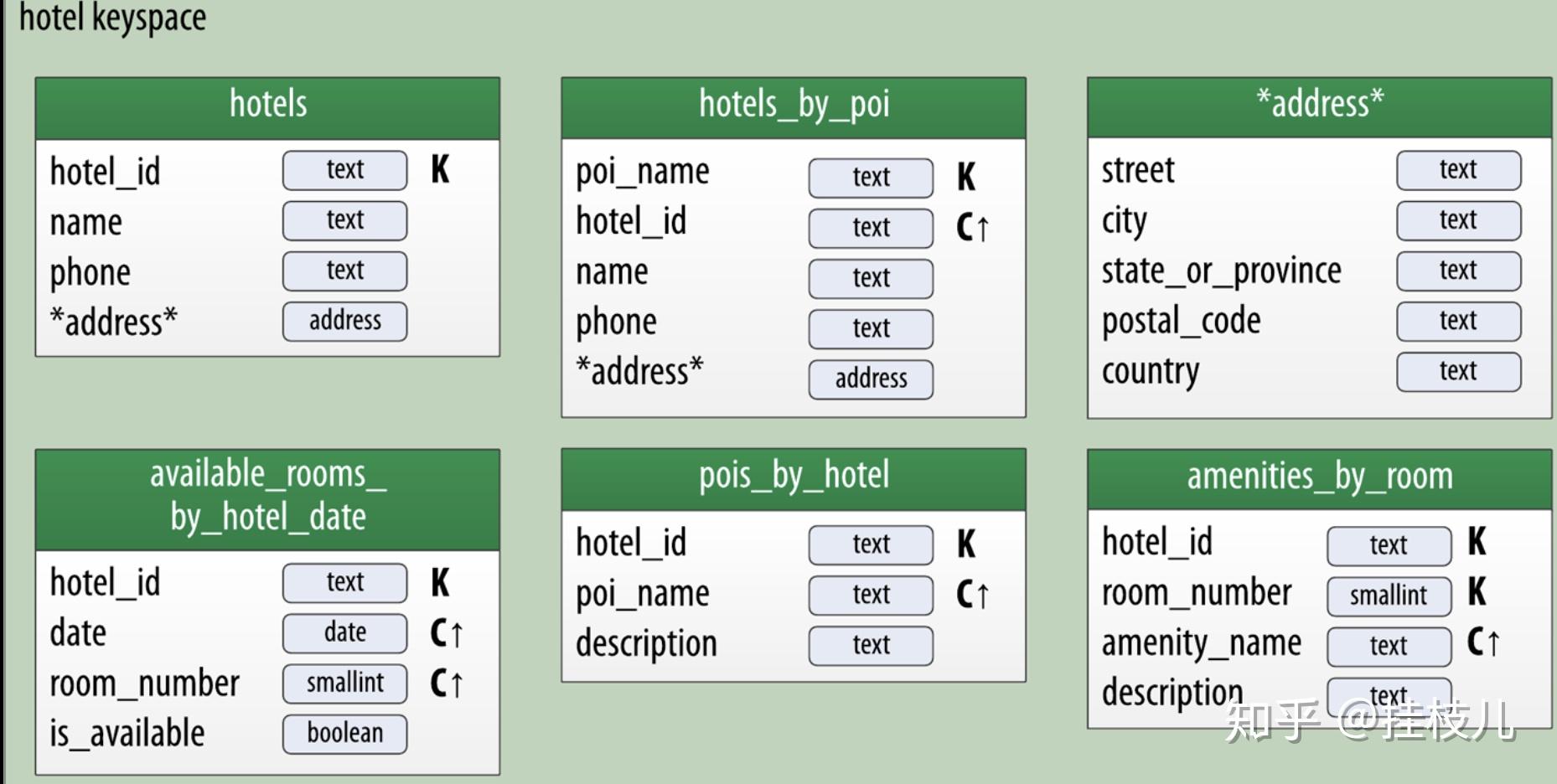
我们把刚刚画的概念图,加入实体数据CHEBOTKO PHYSICAL DIAGRAMS图。(标准的画法是这样的)
酒店预订的实体模型,涉及到2个表

1.3.6 建表语句
1 | CREATE KEYSPACE hotel |
书中建议定义的partition key都要按照(key)的方式包起来,来保证定义清晰。
响应的,我们定义erservation的Keyspace 和对应的数据表
1 | CREATE KEYSPACE reservation |
参照
1 | Cassandra权威指南第一版 |


- 本文作者: 初心
- 本文链接: http://funzzz.fun/2020/12/30/cassandra学习3---实例分析/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!